Archiving an Archive
My Adventures Scraping the Contents of the Archive of Digital Art
A while ago, I wrote my own little suite of applications to learn about web scraping. It is based on Puppeteer/Node.js and grabs content from the Archive of Digital Art (ADA), parses it into JSON and extracts the images. Along the way I learned a lot about ADA, the ethical concerns and technical pitfalls of web scraping.
Join me as I scrape the bottom of the web archive.
February 2024
 (Source:
Dall-E in ChatGPT)
(Source:
Dall-E in ChatGPT)
Introduction
A few years ago, I studied Media Art Histories at DUK, the Danube University Krems (since then it was renamed to "University for Continuing Education" just to ruffle everyone's feathers). As part of my master's thesis, I wrote my own little web archive for digital art. It was a rickety odd thing with an Angular frontend, an Express/Node.js backend using MongoDB. I used Auth0 for user registration and authentication. I deployed the whole thing to Heroku and used Imgur for image hosting because I'm cheap.
Needless to say, if I were to do it again, I'd do it differently, cleaner and simply better. I had just taken my first steps into proper web development and had much to learn.
Not unlike Elizabeth Debicki's character Ayesha in Guardians of the Galaxy Vol. 2, I decided to call my digital archive ADAM, the Archive of Demo Art and Media. You can read more details about ADAM here and find my master's thesis here.
The topic of my master's thesis was the Atari ST demoscene in the 1980s. This is a scene of enthusiasts who produce realtime, audio-visual demo art. I submitted ADAM as a possible solution for a web archive of computer demos. After I had finished programming the first version, I wanted to populate it. I had added a dozen articles with images and links using stock photos. But I wanted to stress test it by populating it with hundreds of articles. Of course, I didn't want to write them myself.
Populating the Demo Archive Through Web Scraping
The university has its own web archive called ADA, the Archive of Digital Art (at digitalartarchive.at). It is operated by what was then called the Department of Image Science (since then it was renamed to the "Centre of Image Science", again probably just to ruffle everyone's feathers). ADA was launched more than two decades ago and is quite a remarkable project. It is an online platform dedicated to the archiving, documenting, and promoting digital art. The goal of ADA is to provide a comprehensive database for scholars, artists, curators, and the general public to explore and understand the rapidly evolving field of digital art. ADA has thousands of articles on artworks, thousands more on exhibitions, literature and institutions.
This would be an ideal source for material to populate my empty archive. I wanted to scrape a few hundred articles and only use the material to test the sturdiness of my own archive. None of it would be exposed to the public because I'd only populate the development environment.
So I reached out to the professor running ADA at the time to ask for his permission. I did this out of courtesy because I knew that ADA does not get a lot of traffic. If I suddenly scraped 500 articles and their related images, I would cause a visible spike in traffic.
Unfortunately, none of my requests got a reply.
I reckoned that the university should help one of thier students. I also knew that large parts of ADA had been funded by publicly financed projects, so there were no commercial interests involved. The university wouldn't need to excert any effort, and my scraping would not incur any additional costs.
So I decided to covertly scrape the Archive of Digital Art. Sneaky, sneaky!
Since I originally scraped the Archive of Digital Art, it has been fully revamped and relaunched. Its structure and design changed (again funded by public money). None of the page URLs match, neither the articles nor the search result pages (the URLs have a completely different structure). So the instructions in this article are no longer applicable without further adaptations. This is why I am sharing the details of my web scraping journey.
The Ethical Issues of Web Scraping
In all fairness, no-one really wants their web content to be scraped and published elsewhere without permission. Users should visit the original website if they want to see the content. I don't contest any of that. The crucial difference is that I did not and do not intend to publish any of the scraped content from ADA.
That being said, let's look at some of the concerns of web scraping in detail.
 Web scraping might have legal issued (Source:
Dall-E in ChatGPT).
Web scraping might have legal issued (Source:
Dall-E in ChatGPT).
Legal and Ethical Concerns
Web scraping can in principle run afoul of the law, especially if it violates a website's Terms of Use. The ADA website does not explicitly prohibit scraping in their Terms. Please see a capture of the old version of the Terms before the relaunch in November 2023. And even the new terms also do not prohibit scraping or the use of the content for Large Language Models (LLMs). Furthermore, scraping can lead to copyright infringement issues when the copyrighted content is republished without permission.
And this is where my intention makes it harmless and acceptable. I only sought and seek to scrape the content for the purpose of learning how to do it. I did not and will not republish it in any way, shape or form.
On websites other than ADA, scraping can raise privacy concerns, if personal data is collected without consent. It can also harm the business model of companies that rely on data exclusivity, and scraped data presented out of context might mislead users or damage the reputation of the original content provider. But ADA provides content that is publicly available and free to access. If any of the entries do contain personal data, it is already out in the pubic and thus is the responsibility of the ADA to remove it.
Technical and Economic Implications
From a technical standpoint, automated scraping can burden servers with excessive requests, degrading the experience for regular users. Sometimes, it can even resemble a Denial of Service (DoS) attack.
The solution to this is to be considerate and not to scrape too many pages in a short time. I set my scraper to a small set of pages at a time and distributed the requests over a longer period of time. I also set the scraper to wait a few seconds between requests to simulate regular human behavior and not interfere with any other visitors on the archive.
No Harm Done
While scraping isn't universally negative (e.g., search engines like Google scrape sites for indexing), I think that it is crucial to approach it responsibly. Respecting a site's robots.txt file and being aware of the potential legal, ethical, and technical ramifications is essential. I definitely don't think that all scraping is harmful, but caution and respect for the source website are paramount.
A Dodgy Copycat of ADA Already Exists
As a final observation about the contents of ADA, I discovered an oddity. There already exists a full replica of ADA. I am unsure if it is an official mirror or a rogue copy. It is hosted at www.archive-digitalart.eu. It is a complete copy of the original ADA, including all the images. Yet it still has the old design. It is even a bad copy because some of its links are broken.
It strikes me as a very odd thing for the university to allow this because a copy of the content might even impede the Google ranking of the original website. The copycat site also features a legal disclaimer that it is operated by the professor who created the original archive. In the German-speaking area, websites are legally required to disclose the entity operating the website in a section often called "Impressum" or "Imprint". The copycat site doesn't even have a proper imprint. And finally, the copycat site does not comply to GDPR, the European General Data Protection Regulation. It does not have a privacy policy, it does not ask for consent to use cookies, and it does not provide a way to delete personal data.
If the university allows a blatant copy of ADA on www.archive-digitalart.eu, then my unintrusive, modest and discrete web scraping is the least of their worries.
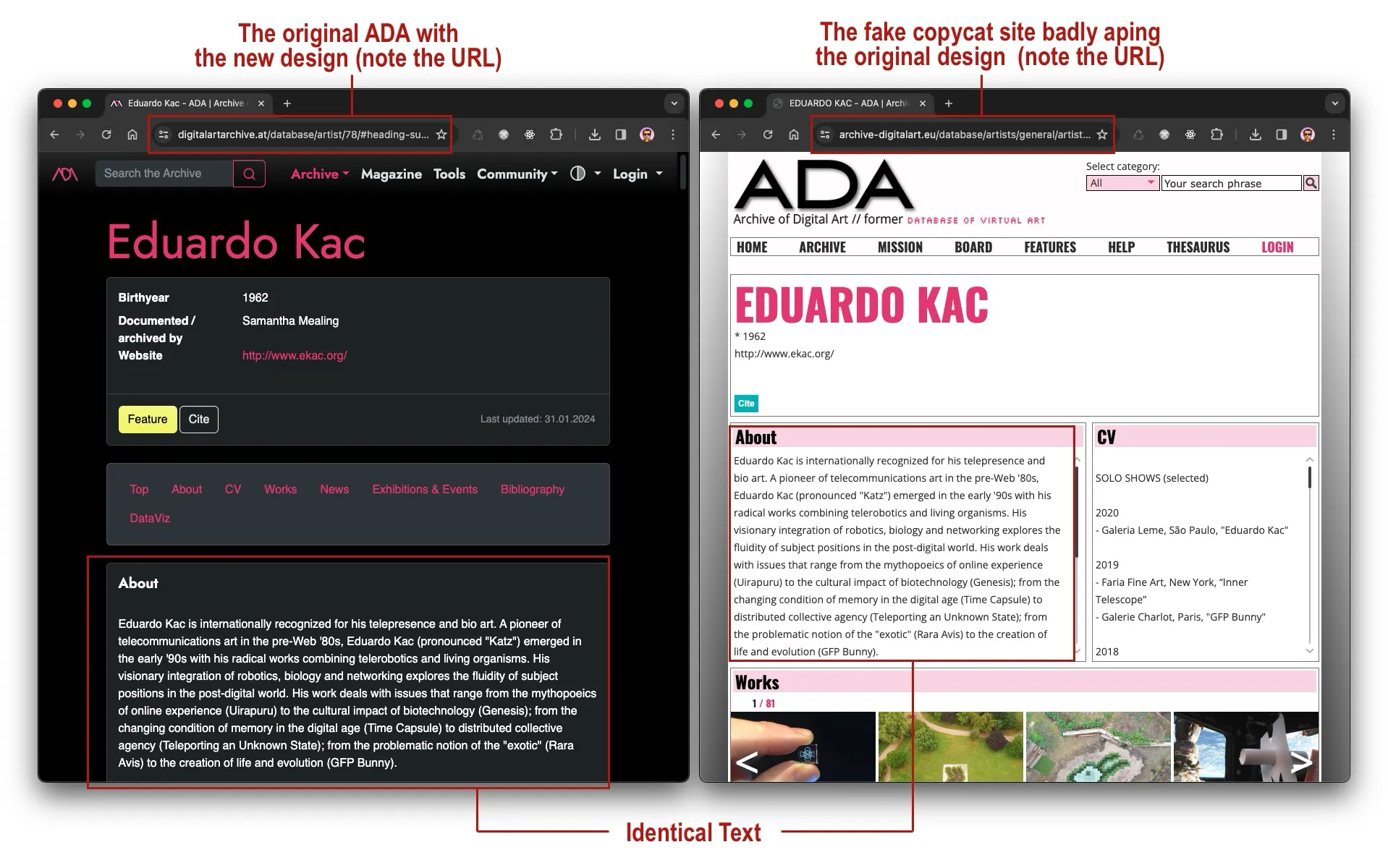 On the left is the relaunched ADA-Website
digitalartarchive.at
showing the article about Eduardo Kac, on the right is the bad
imitation at
www.archive-digitalart.eu
showing the identical text from the original ADA (Source:
screenshots).
On the left is the relaunched ADA-Website
digitalartarchive.at
showing the article about Eduardo Kac, on the right is the bad
imitation at
www.archive-digitalart.eu
showing the identical text from the original ADA (Source:
screenshots).
Reasons for Scraping the Archive
For my little exercise, I only needed a couple of hundred of the thousands of articles. Potentially, you or anyone else could scrape the whole Archive of Digital Art. As long as the content is not released to the public as a duplicate, it might even be beneficial for ADA.
Archiving ADA by scraping its content has numerous benefits. First of all, it ensures the preservation of the available data, safeguarding against loss or modification. By saving the data at a different location, there will be a copy a past of state of ADA enshrined in amber like the mosquito that gave life to the dinosaurs in Steven Spielberg's Jurassic Park. Given the risk of publicly financed project of losing their funds, there is a non-zero risk of ADA disappearing at some point. The scraped copy provides a backup in case of disasters, preventing data loss.
Additionally, archiving the data aids research, allowing analysis of trends and patterns. By having the data stored locally, the offline copy can be used for the analysis instead of constantly accessing the online version and producing web traffic that would skew the statistics and potentially increase the server costs. I only ended up scraping three to four hundred pages.
Having the data scraped and stored safely promotes transparency and accountability by preserving this public information. Legal compliance is ensured, meeting regulations that require the preservation of the data. Furthermore, this produces historical documentation and offers insights into past versions of the ADA-Website with their previous data showing the cultural shifts.
Finally, the archived data serves educational purposes, facilitating learning and experimentation. And this is what I want to do. I learned about web scraping, by scraping ADA.
Let's Get Scraping!
The web scraper I wrote is precisely tuned to the old design of the Archive of Digital Art (ADA). Since the relaunch, the design has changed drastically in layout and naming of the IDs with the content. You'd need to analyse the site again with the new design and adapt the scraper. Nevertheless, there is a lot to learn from the process. This project is an example for the crawl and capture of a large amount of modestly complex content.
Here is an overview of the general process of scraping ADA:

GitHub Repository of Archive Scraper
Please find this project's GitHub-Repository here: Archive Scraper
Installation
To run the scraper, you need to have Node.js installed. Clone the
repository and run npm install to install the
dependencies. Then please follow the instructions below for each
individual component.
It's All In the Preparation
The different components of the scraper crawl the archive, save the content, find the image URLs and - where applicable - the related large images. Then download the image files and save them.
The final component runs through all of the locally saved HTML files and extracts their relevant content and saves it in JSON format.
ADA has many thousands of pages with artists, works, events, etc. Before we can scrape the content, we need a list of all URLs. Then we can run through them and grab their content for further processing. If you scrape the whole ADA website, you will have around gigabytes of data (with all the text and the images small and large where applicable).
Before writing any code and running the web scraper, we need to analyse the structure of ADA.
These are the categories in ADA:
- artists
- events
- institutions
- literature
- scholars
- works
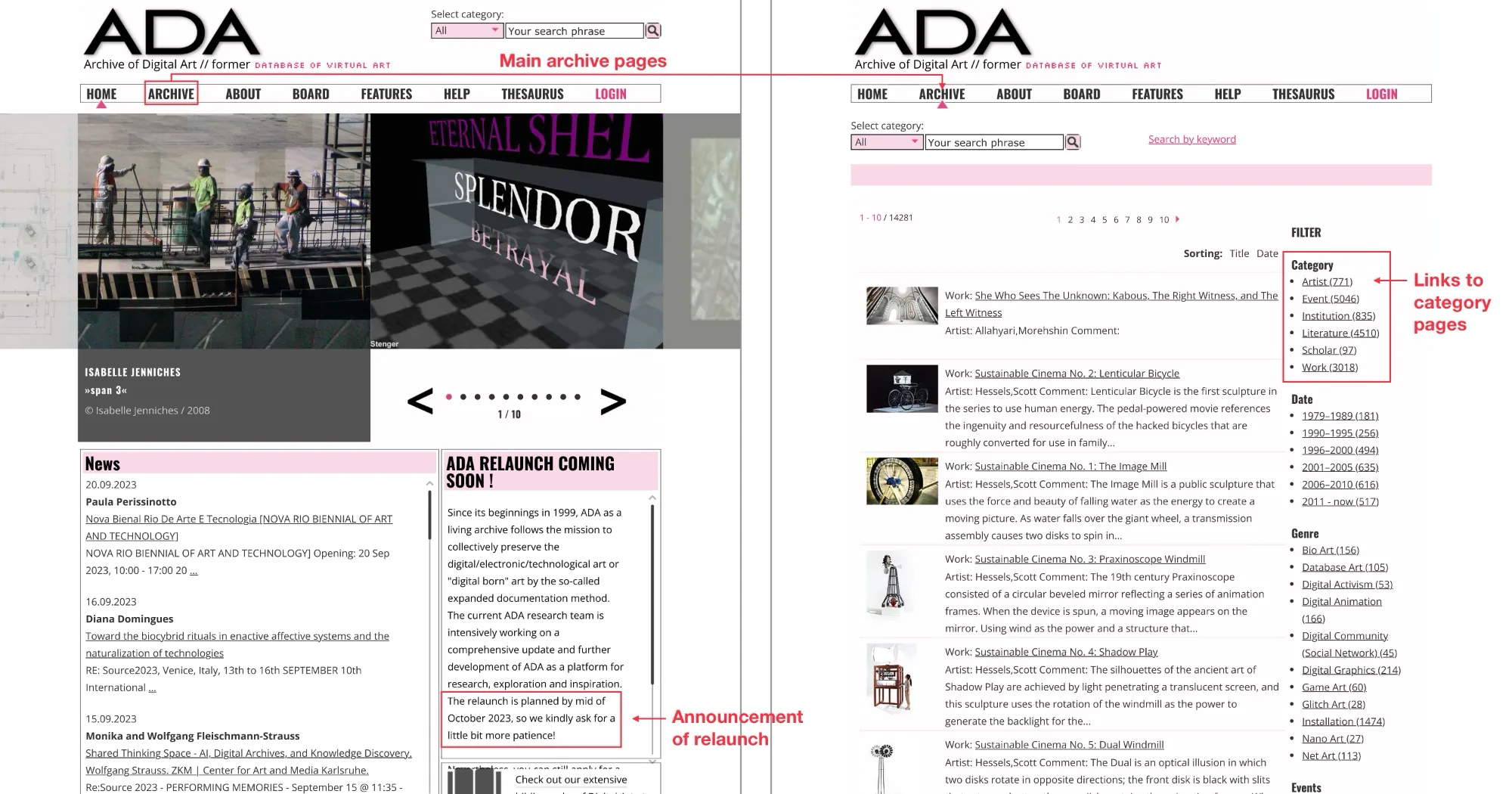 On the left is the front page of ADA, on the right the main
archive page with all the different categories (Source:
sceenshots).
On the left is the front page of ADA, on the right the main
archive page with all the different categories (Source:
sceenshots).
Please note: All the components need to run in the order they are listed here. The first component generates the input for the second component, and so on.
1. Get all Pages with the Search Results
Crawl ADA for the Search Results Pages of Each Category
First of all, we need to get the URLs of all search results pages
for each category. This it the task of the component
1_get_search_result_pages.js. So we crawl ADA for the
search results and save them to a JSON file. This will be the
basis for the next steps.
1.1 Usage of 1_get_search_result_pages.js
We launch 1_get_search_result_pages.js. As its
first argument, this application takes the URL of
the first page of the search results for a category (e.g. artists,
works, literature, etc.). The app is launched by entering:
node 1_get_search_result_pages.js ARG1 ARG2It then checks the number of available search result pages for this category and generates a JSON file with the remaining search result URLs for this category.
As its second argument it takes the path to the destination JSON file. You'll have to repeat this for all the categories on ADA.
Here's a reminder of the available categories:
Artists
https://digitalartarchive.at/database/database-info/archive.html?tx_kesearch_pi1%5Bpage%5D=1&tx_kesearch_pi1%5Bfilter%5D%5B2%5D%5B2%5D=artist
Events
https://digitalartarchive.at/database/database-info/archive.html?tx_kesearch_pi1%5Bpage%5D=1&tx_kesearch_pi1%5Bfilter%5D%5B2%5D%5B14%5D=vaexh
Institutions
https://digitalartarchive.at/database/database-info/archive.html?tx_kesearch_pi1%5Bpage%5D=1&tx_kesearch_pi1%5Bfilter%5D%5B2%5D%5B18%5D=vainst
Literature
https://digitalartarchive.at/database/database-info/archive.html?tx_kesearch_pi1%5Bpage%5D=1&tx_kesearch_pi1%5Bfilter%5D%5B2%5D%5B12%5D=Literature
Scholars
https://digitalartarchive.at/database/database-info/archive.html?tx_kesearch_pi1%5Bpage%5D=1&tx_kesearch_pi1%5Bfilter%5D%5B2%5D%5B35%5D=scholar
Works
https://digitalartarchive.at/database/database-info/archive.html?tx_kesearch_pi1%5Bpage%5D=1&tx_kesearch_pi1%5Bfilter%5D%5B2%5D%5B4%5D=work
1.2 Example
In this example, the component takes the URL of the first category page of artists and the destination path to save the found artist search result page URLs into a JSON file.
node 1_get_search_result_pages.js https://digitalartarchive.at/database/database-info/archive.html?tx_kesearch_pi1%5Bpage%5D=1&tx_kesearch_pi1%5Bfilter%5D%5B2%5D%5B2%5D=artist ./scrape/1_urls/a_category_index/artist-test-urls.json2. Get all Pages of a Category
Get All the Article URLs from the Search Result Pages
Now that we have all the search page URLs, we need to read them
from the JSON files and then scrape the pages for the actual
article URLs. This is the job of 2_get_page_urls.js.
2.1 Usage of 2_get_page_urls.js
The component takes two arguments. The first one is the file path to the JSON file with the search result URLs, and the second one is the file path to save the found article URLs into a JSON file.
node 2_get_page_urls.js ARG1 ARG22.2 Example
In this example, the component takes the file path to the JSON file with the search result URLs and the file path to save the found article URLs into a JSON file.
node 2_get_page_urls.js ./scrape/1_urls/a_category_index/artist-test-urls.json ./scrape/1_urls/b_page_urls/artist-pages-test-urls.jsonThis component is the same for all categories. You will have to run it for each category separately (artists, events, institutions, literature, scholars, works). It reads the search URL JSON files and then crawls the search result pages for the actual article URLs. It then saves them into a JSON file.
 On the left, the search result page for events, on the right,
the details page of an event (Source: sceenshots). This
component uses the information on the left to find all the links
to the pages on the right.
On the left, the search result page for events, on the right,
the details page of an event (Source: sceenshots). This
component uses the information on the left to find all the links
to the pages on the right.
3. Crawl the Content
Get all the page contents and regular images (main web archive content scraper)
Now we are ready to crawl the actual contents of the pages using
3_crawl-content.js. This component takes a JSON list
of URLs, scrapes the content of each page and saves it. It was
important to first analyse the structure of the pages, note all
the IDs of the Divs and sections, and then write the scraper to
extract the relevant data.
3.1 Usage of 3_crawl-content.js
Open the app with
node 3_crawl-content.js ARG1 ARG2 where the first
argument is the file path to the URL list and the second one is
the type of content to scrape.
3.2 Example
node 3_crawl-content.js ./scrape/1_urls/page-urls/work-urls.json worksThis component is the most complex one. It is based on the analysis of the structure of the pages. It is not a general purpose component. It is adapted to the specific areas of a typical page in the different categories of ADA. You will have to run it for each category separately (artists, events, institutions, literature, scholars, works).
Here is an example of the structure of the pages in the 'artist' category:
 On the left, the search result page for artists, on the right,
the details page of an artist (Source: sceenshots). This
component uses the information on the right to identify the
relevant content and read it.
On the left, the search result page for artists, on the right,
the details page of an artist (Source: sceenshots). This
component uses the information on the right to identify the
relevant content and read it.
4. Get Large Images for Each Thumbnail
Many of the articles in the 'works' category have images. The thumbnails on the pages show the small version of an image. When a user clicks on one of them a larger version opens in a new window.
The component
4_lg_img1_get-urls-of-large-images.js reads the
thumbnail URLs and converts them to the assumed URLs of the
respective large images and saves them into a JSON file. This is
only applicable to the category 'works', none of the other
categories have large versions of their images.
4.1 How Does It Work?
All settings in the component are already set for the
'works' category. The HTML files are read from the
directory /scrape/pages/works/ and then crawled for
the thumbnail images, their URLs are then converted into the
assumed URL of the corresponding large images. This assumption is
mostly correct. These new URLs are saved in a JSON file together
with the original thumbnail image URLs (for later reference). This
file works_large_images.json is saved in the
scrape/1_urls/c_image_urls directory.
In the next component, the URLs are used to download the large images. Please note that you will need to have the works pages downloaded in the folder works before you can run this component.
4.2 Usage of 4_lg_img1_get-urls-of-large-images.js
As all the settings are predefined already to use the 'works' category, you simply need to launch the application with:
node 4_lg_img1_get-urls-of-large-images.js5. Download the Large Image Files
The component
5_lg_img2_download-large-images.js reads the large
image URLs from works_large_images.json an uses them
to download the large images from the web.
Not all thumbnail images actually have a large version, and in
some cases, there might even be an issue while downloading. To
keep track of this, any failed downloads are logged in
./4_download_log/works_lg_images_failed.txt.
The downloads can then be repeated for the failed files. Keep in mind that there might not be a large image.
5.1 Usage of 5_lg_img2_download-large-images.js
Everything is set up to use the JSON file generated in the previous component. You simply launch:
node 5_lg_img2_download-large-images.js6. Parse the Downloaded Pages
Read the Data from the HTML Files and Save it as JSON
6_parse_offline_pages.js is the final component that
actually reads the HTML files and extracts the relevant data from
them. It then saves the data in JSON format in a massive file.
This component it adapted to the specific areas of a typical page in the different categories of ADA. It is not a general purpose component. You will have to run it for each category separately (artists, events, institutions, literature, scholars, works). Please keep in mind that the generated JSON file will be very large. For example, the 'works' category has more than 2,000 items. The 'events' category has nearly 5,000 items.
The local HTML files are parsed, so if the parsing fails at some point, the component will stop. You can then move the HTML files that have already been parsed out of the respective category folder, and then restart the component. It will continue where it left off. In the rare case that an HTML file is invalid or broken and the parsing fails, you can move it out of the folder and restart the component.
6.1 Usage 6_parse_offline_pages.js
The component takes one argument, the category for which it should run. Open the app with:
node 6_parse_offline_pages.js ARG1As previously noted, the categories are: artists, events, institutions, literature, scholars, work:
6.2 Example
node 6_parse_offline_pages.js scholars6.3 Additional Notes on this Component
The presets in the component are specific to the typical pages in the individual categories.
The parser runs through the HTML and pulls the content from the divs with specific class names. The structure of the pages and their class names differs between the different categories.
If you want to use this component for another website, you will
have to adapt it to the structure of the pages on that website.
The configuration of the class names is in component file
6_parse-offline-pages.js. The class names are defined in the
variable typeData and listed by category name.
The End of the Scraping Journey
My journey through scraping the Archive of Digital Art has been both enlightening and challenging. Despite encountering technical hurdles and ethical considerations along the way, I've gained invaluable insights into web scraping and the importance of responsible data handling.
While my initial intention was to populate my own digital archive for experimentation and learning, the process evolved into a deeper understanding of the complexities surrounding web scraping. Through careful consideration of legal, ethical, and technical implications, I've navigated the intricacies of extracting data from ADA while respecting its integrity and purpose.
Moreover, my experience underscores the significance of archiving digital content like ADA. By preserving this valuable repository of digital art, we ensure its accessibility for future research, analysis, and educational purposes. The scraped data not only serves as a backup against potential loss but also facilitates transparency, accountability, and historical documentation.
Moving forward, it's imperative to approach web scraping with mindfulness and responsibility, acknowledging the potential impact on website owners and users alike. As I wrap up this chapter of my scraping journey, I'm reminded of the importance of ethical conduct and adherence to legal frameworks in the digital landscape.
In the end, my efforts to scrape ADA has been not only a technical exercise but also the value of preserving digital resources for the betterment of scholarship and creativity. As I close this chapter, I'm grateful for the lessons learned and the opportunities for growth that lie ahead in web development and data management.
Bonus: PDF Files
Some of the articles on ADA have links to PDF files. To get the PDF files, we need to extract their URLs from the downloaded content and then in a second step download the PDF files.
Get the PDF URLs
The PDF scraper first needs to run through all of the HTML files
in the Literature category and extract the URLs of the PDF files.
This is initiated with the command
node pdf1_get_pdf_urls.js
Most Literature pages do not have PDF links, but the scraper needs
to check all of them. The PDF scraper then saves the list of PDF
URLs in the file
./scrape/1_urls/c_image_urls/literature_pdf_urls.json. This file is then used by the PDF downloader to download the
PDF files.
While the PDF URL scraper is running, make sure it is not interrupted. The JSON file it generates is not yet fully compliant. It is missing the opening an closing square brackets and has a comma at the end of every entry, including the last one. This is the reason why some IDEs will flag the file as incorrect if you look at it before the scraping has finished. Both the brackets and the trailing comma are fixed at the very end of the scrape.
If you happen to interrupt the process, then you can fix the file yourself by simply inserting an opening square bracket at the beginning, removing the last comma and adding the closing square bracket at the end.
Download PDF Files
Once the PDF URLs have been saved to the JSON file, you can run
the PDF downloader with node pdf2_download.js. This
will download and save the PDF files locally.